We know that statistics (which is different from mathematics) plays an important role in various other sciences (mathematics is not a science, it’s an art). But still I would like to discuss one very interesting application to linguistics. Consider the following two excerpts from an article by Bob Holmes:
1. ….The researchers were able to mathematically predict the likely “mutation rate” for each word, based on its frequency. The most frequently used words, they predict, are likely to remain stable for over 10,000 years, making these cultural artifacts, or “memes”, more stable than some genes…..
2. ….The most frequently used verbs (such as “be”, “have”, “come”, “go” and “take”) remained irregular. The less often a verb is used, the more likely it was to have been regularised. Of the rarest verbs in their list, including “bide”, “delve”, “hew”, “snip” and “wreak”, 91% have regularised over the past 1200 years…….
The first paragraph refers to the work done by evolutionary biologist Mark Pagel and his colleagues at the University of Reading, UK. Also, “mathematically predicted” refers to the results of the statistical model analysing the frequency of use of words used to express 200 different meanings in 87 different languages. They found the more frequently the meaning is used in speech, the less change in the words used to express it.
The second paragraph refers to the work done by Erez Lieberman, Jean-Baptiste Michel and others at Harvard University, USA. All people in this group have mathematical training.
I found this article interesting since I never expected biologists and mathematicians spending time on understanding evolution of language and publishing the findings in Nature journal. But this reminds me of the frequency analysis technique used in cryptanalysis:

 , the number of binding sites, and
, the number of binding sites, and  , the
, the 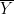 , for
, for  and
and 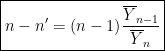
 and
and  ;
;  is allosteric constant and
is allosteric constant and  is the concentration of ligand under some normalizaton conditions.
is the concentration of ligand under some normalizaton conditions. ,
, 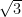 ,
, 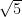 and
and  are irrational numbers – Burkard Polster (13 April 2018)
are irrational numbers – Burkard Polster (13 April 2018)
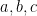 be arbitrary integers. Then the congruence
be arbitrary integers. Then the congruence  has a non-trivial solution modulo any prime
has a non-trivial solution modulo any prime  .
. be a non-singular
be a non-singular 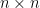 matrix with real elements, and let
matrix with real elements, and let  be a lattice. If
be a lattice. If 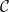 is a set in
is a set in 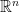 that is convex, symmetric about origin
that is convex, symmetric about origin 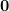 , and if
, and if  , then there exists a lattice point
, then there exists a lattice point  such that
such that 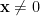 and
and  .
. , where
, where  are non-negative integers.
are non-negative integers.
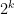 if and only if
if and only if  is prime.
is prime.
 in the list for which
in the list for which  is an integer, replace
is an integer, replace 


 , we will work with a little bit more general equation, namely:
, we will work with a little bit more general equation, namely:  , where
, where 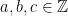 . For proofs, one can refer to section 5.5 of Niven-Zuckerman-Montgomery’s An introduction to the theory of numbers.
. For proofs, one can refer to section 5.5 of Niven-Zuckerman-Montgomery’s An introduction to the theory of numbers. are
are 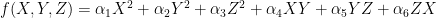 due to the following lemma:
due to the following lemma: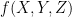 can be written as an equation of the form
can be written as an equation of the form  with
with  .
.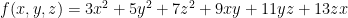 , and we want to determine whether this
, and we want to determine whether this  has a non-trivial solution. Firstly, we will do change of variables:
has a non-trivial solution. Firstly, we will do change of variables:
 ,
, 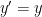 and
and  . Thus
. Thus
 ,
, and
and  . Thus
. Thus
 ,
, 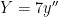 and
and  . Now we apply the theorem to
. Now we apply the theorem to  . Since all the coefficients are prime numbers, we can use
. Since all the coefficients are prime numbers, we can use  is quadratic residue mod -3, is same as
is quadratic residue mod -3, is same as 


You must be logged in to post a comment.