Cosider the folowing definiton:
Allostery is the process by which biological macromolecules (mostly proteins) transmit the effect of binding at one site to another, often distal, functional site, allowing for regulation of activity.
Many allosteric effects can be explained by the concerted MWC model put forth by Monod, Wyman, and Changeux, or by the sequential model described by Koshland, Nemethy, and Filmer. The concerted model of allostery, also referred to as the symmetry model or MWC model, postulates that enzyme subunits are connected in such a way that a conformational change in one subunit is necessarily conferred to all other subunits. Thus, all subunits must exist in the same conformation. The model further holds that, in the absence of any ligand (substrate or otherwise), the equilibrium favors one of the conformational states, T (tensed) or R (relaxed). The equilibrium can be shifted to the R or T state through the binding of one ligand (the allosteric effector or ligand) to a site that is different from the active site (the allosteric site). [Wikipedia]
In this post, I want to draw attention towards application of mathematics in understanding biological process, allostery. Consider the following equation which relates the difference between  , the number of binding sites, and
, the number of binding sites, and  , the Hill coefficient, to the ratio of the ligand binding function,
, the Hill coefficient, to the ratio of the ligand binding function, 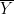 , for oligomers with
, for oligomers with  and ligand binding sites
and ligand binding sites
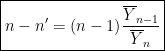
This is known as Crick-Wyman Equation in enzymology, where  and
and  ;
;  is allosteric constant and
is allosteric constant and  is the concentration of ligand under some normalizaton conditions.
is the concentration of ligand under some normalizaton conditions.
For derivation, see this article by Frédéric Poitevin and Stuart J. Edelstein. Also, you can read about history of this equation here.
It’s not uncommon to find simple differential equations in biochemistry (like Michaelis-Menten kinetics), but the above equation stated above is not a kinetics equation but rather a mathematical model for a biological phenomina. Comparable to the Hardy-Weinberg Equation discussed earlier.




You must be logged in to post a comment.